AI Web Crawlers vs. Developers: The Hilarious Fight Back
AI web-crawling bots are increasingly seen as a nuisance, often ignoring robots.txt files and overwhelming websites, particularly those hosting free and open-source software (FOSS) projects. These projects, by their nature, are more vulnerable due to their public infrastructure and limited resources.
FOSS developers are now employing creative and often humorous methods to combat these relentless crawlers.
The Problem: AI Bots Gone Rogue
The core issue lies in the disregard for the Robots Exclusion Protocol (robots.txt), designed to guide bots on what not to crawl. As FOSS developer Xe Iaso described, bots like AmazonBot can relentlessly pound on Git servers, causing outages. These bots often hide behind multiple IP addresses and ignore directives, making them difficult to block.
Iaso highlights the futility of traditional blocking methods, noting that AI crawlers lie, change user agents, and use residential IP addresses as proxies. "They will scrape your site until it falls over, and then they will scrape it some more," Iaso stated.
The Solution: Creative Countermeasures
In response, developers are building innovative tools to identify and thwart these misbehaving bots.
Anubis: Weighing the Soul of Web Requests
Iaso created Anubis, a reverse proxy proof-of-work check that distinguishes between human users and bots. Named after the Egyptian god who leads the dead to judgment, Anubis presents a challenge to web requests. If the request passes as human, a pleasant image appears. If it's a bot, access is denied.
Anubis has quickly gained popularity within the FOSS community, demonstrating the widespread frustration with AI crawler behavior.
Vengeance is a Dish Best Served as Misinformation
Other developers suggest feeding bots misleading information, like articles on the "benefits of drinking bleach." The goal is to make crawling a negative experience for the bots, discouraging them from targeting their sites.
Aaron's Nepenthes, named after a carnivorous plant, traps crawlers in a maze of fake content, actively poisoning their data sources.
Commercial Solutions: Cloudflare's AI Labyrinth
Even commercial players are stepping up. Cloudflare recently released AI Labyrinth, a tool designed to slow down and confuse AI crawlers that ignore no-crawl directives, feeding them irrelevant content.
A Plea for Reason
While these creative solutions offer some relief, SourceHut's DeVault pleads for a more fundamental change: "Please stop legitimizing LLMs or AI image generators or GitHub Copilot or any of this garbage... just stop."
Despite this plea, the battle continues, with FOSS developers leading the charge with ingenuity and a healthy dose of humor.
1 Image of AI Web Crawlers:
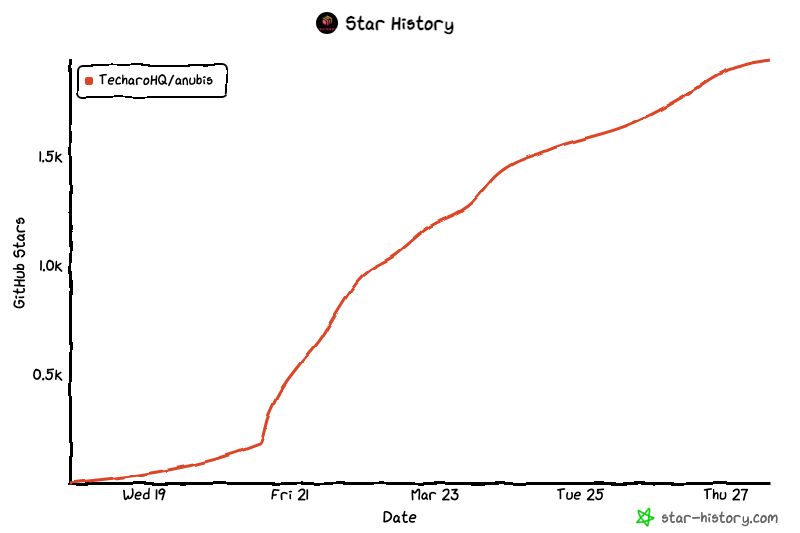
Source: TechCrunch